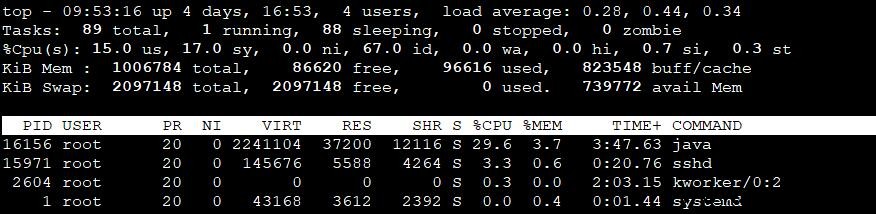
问题现象:spring cloud项目,一定时间后更新某个微服务,启动时去config配置中心查找配置时报错。重启config可以解决,但是没找到具体原因。
后来发现/tmp目录下有tomcat.和config-repo开头的文件,推测是config生成的配置信息存在这里。tmp目录会被系统自动清理导致。
然后特意查了下资料解决。
关于tmp目录清理的资料来自:https://blog.51cto.com/kusorz/2051877
CentOS6以下系统(含)使用watchtmp + cron来实现定时清理临时文件的效果,这点在CentOS7发生了变化,在CentOS7下,系统使用systemd管理易变与临时文件,与之相关的系统服务有3个:
systemd-tmpfiles-setup.service :Create Volatile Files and Directories
systemd-tmpfiles-setup-dev.service:Create static device nodes in /dev
systemd-tmpfiles-clean.service :Cleanup of Temporary Directories
# 相关的配置文件也有3个地方:
/etc/tmpfiles.d/*.conf
/run/tmpfiles.d/*.conf
/usr/lib/tmpfiles.d/*.conf
# 清理/tmp目录规则配置文件路径:
[root@node7 ~]# cat /usr/lib/tmpfiles.d/tmp.conf
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
# See tmpfiles.d(5) for details
# Clear tmp directories separately, to make them easier to override
v /tmp 1777 root root 10d
v /var/tmp 1777 root root 30d
# Exclude namespace mountpoints created with PrivateTmp=yes
x /tmp/systemd-private-%b-*
X /tmp/systemd-private-%b-*/tmp
x /var/tmp/systemd-private-%b-*
X /var/tmp/systemd-private-%b-*/tmp
# 查看详细帮助文档执行下面命令
[root@node7 ~]# man tmpfiles.d
v
Create a subvolume if the path does not exist yet and the file system supports this (btrfs). Otherwise create a
normal directory, in the same way as d.
x
Ignore a path during cleaning. Use this type to exclude paths from clean-up as controlled with the Age parameter.
Note that lines of this type do not influence the effect of r or R lines. Lines of this type accept shell-style
globs in place of normal path names.
X
Ignore a path during cleaning. Use this type to exclude paths from clean-up as controlled with the Age parameter.
Unlike x, this parameter will not exclude the content if path is a directory, but only directory itself. Note that
lines of this type do not influence the effect of r or R lines. Lines of this type accept shell-style globs in place
of normal path names.
通过帮助文档可以看到v参数用来创建一个不存在的目录,x参数用来忽略清理的文件or目录,X参数用来忽略目录,但目录下的文件还会被清理。
通过上面规则可见/tmp是10天清理一次,spring cloud的config服务运行后会在/tmp下生成tomcat.和config-repo开头的目录(我不确定命名是否为固定的还是开发人员可以自己修改),超过10天后就会被清理。
当其他服务模块启动时会去config服务查配置信息,但是目录被清理就会报错,此时重启config,再启动服务即可。
最终解决方法有2个,第一忽略清理/tmp/下指定开头的文件,第二修改jar包运行时的临时目录。
1、编辑/usr/lib/tmpfiles.d/tmp.conf 追加:
x /tmp/tomcat.*
x /tmp/config-repo*
2、采用修改jar包运行时-Djava.io.tmpdir参数实现(我所采用的方法):
java -jar -Djava.io.tmpdir=./tmp # 在当前jar包目录下手动创建一个tmp目录,用于保存config配置信息。
问题才解决。